Introduction to Hive
Difference between SQL and NoSQL
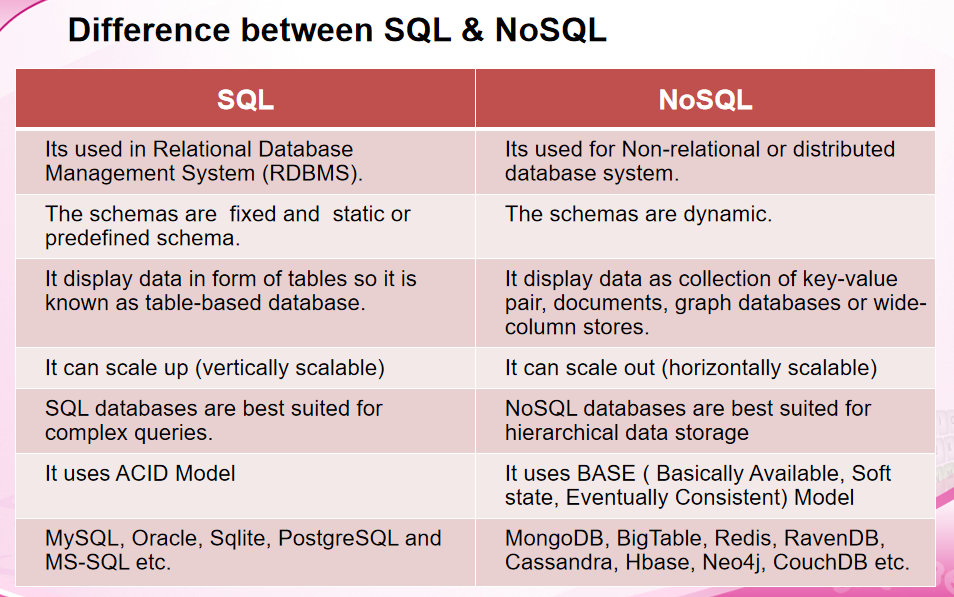
- SQL
Relational, Analytical(OLAP) - NoSQL
Document, Key-Value, Column-Family, Graph
What is Hive
It is an open-source data warehouse system for querying and analyzing large data set stored in HDFS.
它是一个开源数据仓库系统,用于查询和分析存储在HDFS中的大数据集。Its highly scalable.
其高度可扩展性。Hive uses HQL(Hive + SQL) for data summarization, querying and analysis.
Hive使用HQL(Hive + SQL)进行数据汇总,查询和分析。HQL will be converted into map reduce jobs by the Hive component.
Hive组件将把HQL转换为map reduce作业
Who developed Hive
Hive was originally developed by Facebook and is now maintained as Apache hive by Apache software foundation.
Hive最初由Facebook开发,现在由Apache软件基金会维护为Apache hive。It is used and developed by biggies such as Netflix and Amazon as well.
它也由Netflix和Amazon等大型公司使用和开发
Why Hive was developed?
Traditional organization uses data warehouses that are based on SQL, with users and developers that rely on SQL queries for extracting data.
传统组织使用基于SQL的数据仓库,而用户和开发人员则依赖SQL查询来提取数据。The Hadoop ecosystem is not just scalable but also cost effective when it comes to processing large volumes of data.
Hadoop生态系统不仅具有可扩展性,而且在处理大量数据时也具有成本效益。It makes getting used to the Hadoop ecosystem an uphill task. And that is exactly why hive was developed.
这使习惯Hadoop生态系统成为一项艰巨的任务。这就是开发Hive的原因。Hive provides SQL intellect, so that users can write SQL like queries called HQL or hive query language to extract the data from Hadoop.
Hive提供了SQL知识,因此用户可以编写类似HQL的查询之类的SQL或Hive查询语言来从Hadoop提取数据。
How and when it can be used?
Hive can be used for OLAP (online analytic) processing.
Hive可用于OLAP(在线分析)处理。It is scalable, fast and flexible.
它具有可扩展性,快速性和灵活性。It is a great platform for the SQL users to write SQL like queries to interact with the large datasets that reside on HDFS filesystem.
对于SQL用户而言,这是一个很棒的平台,可以编写类似于查 询的SQL来与驻留在HDFS文件系统上的大型数据集进行交互
When Hive cannot be used?
- It is not a relational database.
- It cannot be used fir OLTP(online transaction) processing.
- It cannote be used for real time updates or queries.
- It cannot be used for scenarios where low latency data retrieval is expected, because there is sa latency in converting the HIVE scripts into MAP REDUCE scripts by Hive.
Features of Hive
It supports different file formats like sequence file, text file, avro file format, ORC file, RC file.
它支持不同的文件格式,例如序列文件,文本文件,avro文件格式, ORC文件,RC文件。Metadata gets stored in RDBMS like derby database.
元数据像derby数据库一样存储在RDBMS中。Hive provides lot of compression techniques, queries on the compressed data such as SNAPPY compression, gzip compression.
Hive提供了许多压缩技术,可以对压缩数据进行查询,例如SNAPPY 压缩,gzip压缩。Users can write SQL like queries that hive converts into mapreduce or tez or spark jobs to query against hadoop datasets.
用户可以编写类似查询的SQL,将配置单元转换为mapreduce或tez或 spark作业,以针对hadoop数据集进行查询。Users can plugin mapreduce scripts into the hive queries using UDF user defined functions.
用户可以使用UDF用户定义的函数将mapreduce脚本插入到配置单元 查询中。Specialized joins are available that help to improve the query performance.
可以使用专用联接来帮助提高查询性能
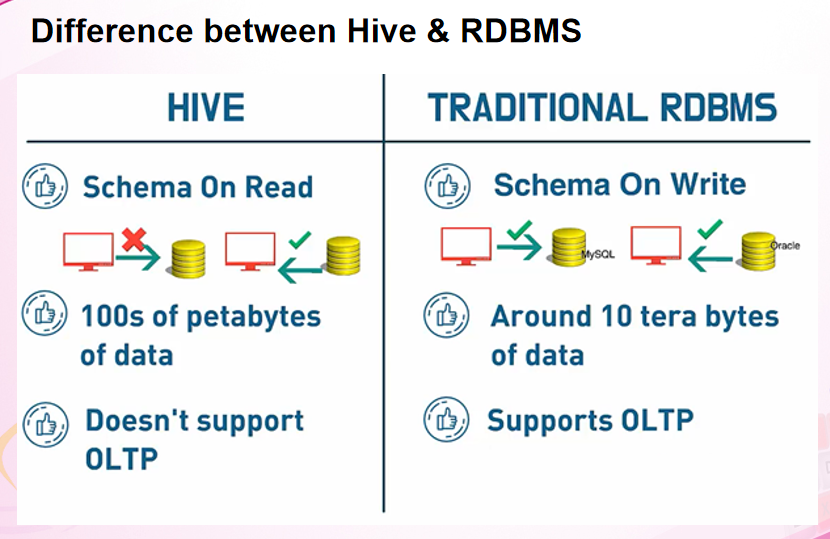
Difference between Hive & RDBMS
Hive Chapter 1
What is Hive?
- HIVE is a data warehouse architecture built on the Hadoop file system.
HIVE是一个建立在Hadoop文件系统上的数据仓库架构。 - HIVE analyzes and manages the data stored in HDFS.
HIVE分析和管理存储在HDFS中的数据。 - It mainly provides the following functions:主要提供以下功能:
Provides a series of tools for extracting / transforming / loading data (ETL)
提供了一系列用于提取/转换/加载数据(ETL)的工具 - Is a mechanism that can store, query, and analyze large-scale data stored in HDFS (or HBase)
是一种可以存储、查询和分析储存于HDFS(或HBase)中的大规模数据的机制 - The query is done through MapReduce (not all queries require MapReduce to complete, such as
select * from XXXis not required;
查询是通过MapReduce完成的(并不是所有的查询都需要MapReduce来完成,例如从XXX中选择select *是不需要的); - In Hive, queries like
select a, b from XXXcan be configured without MapReduce through configuration.
在Hive中,像从XXX中选择a, b这样的查询可以在没有MapReduce的情况下通过配置进行配置。
How to analyze and manage data? 如何分析和管理数据?
- Hive defines a SQL-like query language called HQL.
Hive定义了一种类似SQL的查询语言,称为HQL。 - Hive can be used to query data directly.
Hive可以用于直接查询数据。 - At the same time, the language also allows developers to develop custom mappers and reducers to handle complex analysis tasks that the built-in mappers and reducers cannot complete.
与此同时,该语言还允许开发人员开发定制的Mappers和Reducers来处理内置的Mappers和Reducers无法完成的复杂分析任务。 - Hive allows users to write their own function UDFs.
Hive允许用户编写自己的函数UDFs。 - There are three types of UDFs in Hive: 在Hive中有三种类型的UDFs:
- User Defined Functions (UDF) 用户定义函数(UDF)
- User Defined Aggregation Functions (UDAF) 用户定义聚合函数(UDAF)
- User Defined Table Generating Functions (UDTF). 用户定义的表生成函数(UDTF)
- Hive parses external tasks into a MapReduce executable plan. MapReduce is a high-latency event.
Hive将外部任务解析为MapReduce可执行计划。MapReduce是一个高延迟的事件。 - Each submission and execution of a task takes a lot of time, which determines that Hive can only handle some high-latency application.
任务的每次提交和执行都需要大量的时间,这决定了Hive只能处理一些高延迟的应用程序 - Hive currently has the following disadvantages: 目前Hive有以下缺点:
- Hive does not support transactions; Hive不支持交易;
- Table data cannot be modified 无法修改表数据
- Columns cannot be indexed 列不能被索引
HIVE Data Storage Model. HIVE数据存储模型
HIVE data is divided into : Hive数据分为:
- Table data : Table data is the data that tables in Hive have
表数据: 表数据是Hive中的表所拥有的数据 - Metadata : Metadata is used to store the data about the table.
元数据: 元数据用于存储关于表的数据。
HIVE Data Storage. Hive数据存储
- Hive is based on the Hadoop distributed file system.
Hive是基于Hadoop分布式的文件系统 - HIVE data is stored in the Hadoop distributed file system.
Hive数据存储在Hadoop分布式文件系统中 - We only need to specify the column and row separators in the data when we create the table.
我们只需要在创建表时指定数据中的列和行分隔符。 - Hive can parse the data.
Hive可以解析数据。 - Importing HDFS data into a Hive table is simply moving the data to the directory where the table is located.
将HDFS数据导入到Hive表中只是将数据移动到表所在的目录中。 - The data in the local file system, need to copy in the same directory of the table.
数据在本地文件系统中,需要复制在相同目录下的表。
Hive Data Models-Table. Hive 数据模型-Table
- Tables in Hive are similar in concept to tables in relational databases.
Hive中的表在概念上与关系数据库中的表相似。 - Each table has a corresponding directory in HDFS to store the table’s data.
每个表在HDFS中都有一个对应的目录来存储表的数据。 - This directory can be accessed through
$ {HIVE_HOME} / conf / hive-site.
可以通过$ {HIVE_HOME} / conf / hive-site访问这个目录。 - The
hive.metastore.warehouse.dirproperty in the xml configuration file is used to configure.hive.metastore.warehouse.dir属性在xml配置文件中进行配置。 - The default value of this property is
/ user / hive / warehouse(this directory is on HDFS). 此属性的默认值是/ user / hive / warehouse(此目录位于HDFS上)。 - We can modify this configuration according to requirement.
我们可以根据需要修改这个配置。
Hive Data Models-External Table. Hive 数据模型
- The external table in HIVE is very similar to the table, but its data is not stored in the directory to which the table belongs but stored elsewhere.
HIVE中的external table(外部表)与该表非常相似,但是它的数据不是存储在该表所属的目录中,而是存储在其他地方。 - If we delete the data of external table, the data pointed to by the external table is not deleted, it deletes the metadata corresponding to the external table
如果我们删除了外部表的数据,external table(外部表)指向的数据并没有被删除,它删除了与external table(外部表)对应的元数据 - If we want to delete the table, all the data corresponding to the table including the metadata will be deleted.
如果要删除该表,则删除该表所对应的所有数据,包括元数据。
Hive Data Models-Partition. Hive 数据模型-Partition
- In Hive, each partition of the table corresponds to the respective directory under the table, and the data of all partitions is stored in the corresponding directory.
在Hive中,表的每个分区对应于表下的各个目录,所有partitions(分区)的数据都 存储在相应的目录中。
Hive Data Models-Bucket. Hive 数据模型-Bucket
- Calculate the hash of the specified column and slice the data according to the hash value.
指定列计算 hash,并根据 hash 值切分数据。 - The purpose is to parallelize each bucket corresponding to a file
其目的是将每个Bucket(桶)对应于一个文件并行化
Hive MetaData
- The metadata in Hive includes the name of the table, the columns and partitions of the table and their attributes
Hive中的元数据包括表的名称、列和表的partitions(分区)以及它们的属性 - HIVE metadata needs to be constantly updated and modified.
HIVE元数据需要不断更新和修改。 - Files in the HDFS system are available for read operation more and does not support frequent modification, hence we cannot store Hive’s metadata in HDFS.
HDFS系统中的文件可用于更多的读取操作,不支持频繁的修改,因此我们不能将Hive的元数据存储在HDFS中。 - Currently Hive stores metadata in databases, such as Mysql and Derby.
目前Hive将元数据存储在数据库中,如MySQL和Derby。
Hive Storage model
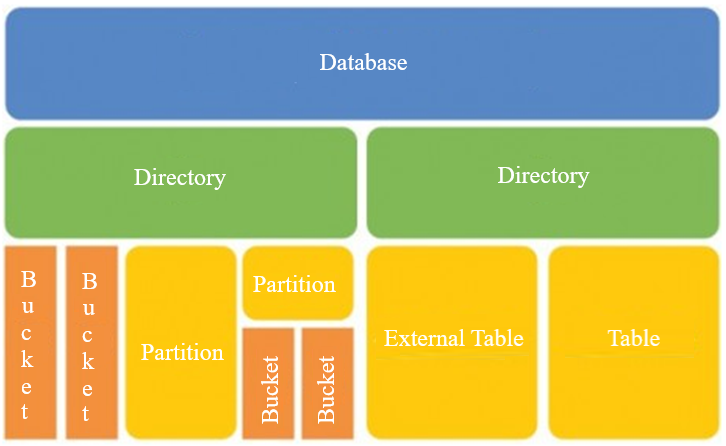
Database Model
The ACID acronym stands for:
- Atomic
All operations in a transaction succeed or every operation is rolled back. - Consistent
On the completion of a transaction, the database is structurally sound. - Isolated
Transactions do not contend with one another. Contentious access to data is moderated by the database so that transactions appear to run sequentially. - Durable
The results of applying a transaction are permanent, even in the presence of failures.
ACID properties mean that once a transaction is complete, its data is consistent (tech lingo: write consistency) and stable on disk, which may involve multiple distinct memory locations.
Write consistency is a wonderful thing for application developers, but it also requires sophisticated locking which is typically a heavyweight pattern for most use cases.
When it comes to NoSQL technologies, most graph databases(including Neo4j) use an ACID consistency model to ensure data is safe and consistently stored.
Here’s how the BASE acronym breaks down:
- Basic Availability
The database appears to work most of the time. - Soft-state
Stores don’t have to be write-consistent, nor do different replicas have to be mutually consistent all the time. - Eventual consistency
Stores exhibit consistency at some later point (e.g., lazily at read time).
BASE properties are much looser than ACID guarantees, but there isn’t a direct one-for-one mapping between the two consistency models (a point that probably can’t be overstated).
A BASE data store values availability (since that’s important for scale), but it doesn’t offer guaranteed consistency of replicated data at write time. Overall, the BASE consistency model provides a less strict assurance than ACID: data will be consistent in the future, either at read time (e.g., Riak) or it will always be consistent, but only for certain processed past snapshots (e.g., Datomic).
The BASE consistency model is primarily used by aggregate stores, including column family, key-value and document stores.
Hive Installation
基于Derby
- 下载
https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-1.2.2/ - 将文件传到Linux
/home/hadoop/Download - 解压
到~/Download目录下找到文件,tar -zvxf apache-hive-1.2.2-bin.tar.gz -C ~/app/ vi ~/.bash_profile在最后添加两行1
2export HIVE_HOME=/home/hadoop/app/apache-hive-1.2.2-bin
export PATH=$PATH:$HIVE_HOME/bin
最后source ~/.bash_profile
- 输入
hive --version查看是否安装成功 开启hadoop
start-all.sh
运行下面的1
2
3
4
5
6hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -mkdir /user/hive/tmp
hdfs dfs -mkdir /user/hive/log
hdfs dfs -chmod g+w /user/hive/warehouse
hdfs dfs -chmod g+w /user/hive/tmp
hdfs dfs -chmod g+w /user/hive/log然后去
/home/hadoop/app/apache-hive-1.2.2-bin/confcopy一下模板修改hive-site.xml和hive-env.sh1
2cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-default.xml
在hive-env.sh中添加vi hive-env.sh1
2
3HADOOP_HOME=/home/hadoop/app/hadoop-2.7.3
export HIVE_CONF_DIR=/home/hadoop/app/apache-hive-1.2.2-bin/conf
export HIVE_AUX_JARS_PATH=/home/hadoop/app/apache-hive-1.2.2-bin/lib
新建hive-site.xml添加vi hive-site.xml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.exec.scratdir</name>
<value>/user/hive/tmp</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/user/hive/log</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:;databaseName=/home/hadoop/app/apache-hive-1.2.2-bin/metastore_db;create=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
</property>
<property>
<name>javax.jdo.PersistenceManagerFactoryClass</name>
<value>org.datanucleus.api.jdo.JDOPersistenceManagerFactory</value>
</property>
<property>
<name>system:java.io.tmpdir</name>
<value>/user/hive/tmp</value>
</property>
</configuration>
初始化数据库
schematool -initSchema -dbType derby加权限
1
2sudo chgrp -R hadoop /user/hive/
sudo chown -R hadoop /user/hive/开启hive
hive
基于Mysql
jar包
mpsql - JDBC https://dev.mysql.com/downloads/connector/j/
这个jar包放在${HIVE_HOME}/lib中,hive-site.xml配置文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.0.104:3306/hive?useSSL=false</value>
<!-- 这里填自己的地址,URL里添加创建数据库好像我的不行 -->
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name> <!-- 用户名 -->
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name> <!-- 密码 -->
<value>hive1234</value>
</property>
<property>
<name>system:java.io.tmpdir</name>
<value>/user/hive/tmp</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.exec.scratdir</name>
<value>/user/hive/tmp</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/user/hive/log</value>
</property>
</configuration>mysql添加用户
1
2
3CREATE DATABASE IF NOT EXISTS hive;
CREATE USER 'hive' IDENTIFIED BY 'hive1234';
GRANT ALL PRIVILEGES ON *.* TO 'hive'@'%' WITH GRANT OPTION;初始化数据库
schematool -initSchema -dbType mysql启动hive
hive
CLI Options
The Hive command line interface (CLI) is used to interact with Hive. Users can use CLI commands to create, manage, and query tables.
Hive命令行接口(CLI)用于与Hive交互。用户可以使用CLI命令来创建、管理和查询表。
You can view the related instructions of Hive through the help command of Hive.
你可以通过Hive的help命令查看Hive的相关指令。 hive --help --service cli
| Usage | Description |
|---|---|
-d,--define <key=value> |
Variable subsitution to apply to hive commands. e.g. hive -d A=B |
--database <databasename> |
Specify the database to use |
-e <quoted-query-string> |
SQL from command line |
-f <filename> |
SQL from file |
-H, --help |
Print help information |
--hiveconf <property=value> |
Use value for give property |
--hivevar <key=value> |
Varibale subsitution to apply to hive commands. |
-i <filename> |
Initialization SQL file |
-S, --silent |
Silent mode in interactive shell |
-v,--verbose |
Verbose mode (echo executed SQL to the console) |
Variable setting
Hive variables are preceded by a namespace, including 4 hiveconf, system, env, and hivevar.
Hive变量前有一个名称空间,包括这4个: hiveconf、system、env和hivevar。
- hiveconf: refers to the value of configuration variables under hive-site.xml.
hiveconf: 指的是hive-site.xml下的配置变量的值。 - system: is a system variable, including the running environment of the JVM.
system: 是一个系统变量,包括JVM的运行环境。 - env: refers to environment variables, including variable information in the Shell environment, such as HADOOP_HOME.
env: 指的是环境变量,包括Shell环境中的变量信息,如HADOOP_HOME。 hivevar: user-defined variable.
hivevar: 用户定义的变量。Ordinary variables can be declared with
--define key = valueor--hivevar key = value, which all represent variables that are hivevar.
普通变量可以用-- define key = value或-- hivevar key = value声明,它们都表示变量是hivevar。hive --hiveconf mapreduce.job.queuename=queue1
This setting is valid for the session started this time and needs to be reconfigured for the next startup.
此设置对这次启动的会话有效,下一次启动需要重新配置。- Set or display variables through set in hive.
通过在Hive中设置或显示变量。set <varname>
Hive Command line
- One-time query 一次性查询
$HIVE_HOME/bin/hive -e 'select a.col from tab1 a'
The progress of mapreduce will be displayed on the terminal. Mapreduce的进度将显示在终端上。
The query results are finally output to the terminal, and hive process exits 查询结果最终输出到终端,Hive进程退出 - Quiet mode query 安静模式查询
$HIVE_HOME/bin/hive -S -e 'select a.ueserid from tab1 log'
Adding-S, will only output the query results to the terminal. 添加–S,仅将查询结果输出到终端。
This silent mode is called by a third-party program, the third-party program obtains the result set through the standard output of hive. 这种静音模式是由第三方程序调用的,第三方程序通过Hive的标准输出获取结果集。 - Execute script 执行脚本
$HIVE_HOME/bin/hive -f /home/my/hive-script.sqlhive-script.sqlis a script file written using hive sql syntax. The execution process is similar to-e, except that sql is loaded from a file.hive-script.sql是一个使用Hive SQL语法编写的脚本文件。执行过程类似于-e,只是SQL是从一个文件加载的。
| Command | Description |
|---|---|
quit/exit |
Exit the interactive shell |
Reset |
Reset configuration to default |
set <key>=<value> |
Modify the value of a specific variableNote: If the variable name is misspelled, no error will be reported |
Set |
Output user-overwritten hive configuration variables |
set -v |
Output all Hadoop and Hive configuration variables |
add FILE[S] <filepath> <filepath>* add JAR[S] <filepath> <filepath>* add ARCHIVE[S] <filepath> <filepath>* |
Add one or more files, jars, archives to the distributed cache |
list FILE[S] list JAR[S] list ARCHIVE[S] |
Outputs resources that have been added to the distributed cache. |
list FILE[S] <filepath>* list JAR[S] <filepath>* list ARCHIVE[S] <filepath>* |
Check if given resource is added to distributed cache |
delete FILE[S] <filepath>* delete JAR[S] <filepath>* delete ARCHIVE[S] <filepath>* |
Deletes the specified resource from the distributed cache |
! <command> |
Execute a shell command from the Hive shell |
dfs <dfs command> |
Execute a dfs command from the Hive shell |
<query string> |
Execute a Hive query and output the results to standard output |
source FILE <filepath> |
Execute a hive script file in the CLI |
HIVE Data Type
Primary data types
TINYINT, SMALLINT, INT, BIGINT, FLOAT, DOUBLE, BOOLEAN, STRING
Complex Data Types
| Type | Description | Example |
|---|---|---|
| ARRAY | A set of ordered fields. Field must be of same type. | Array(1, 2) |
| MAP | An unordered set of key/value pairs. The key type must be atomic, the value can be any type. The key type of the same mapping must be the same, and the value type must be the same. | Map('a', 1, 'b', 2) |
| STRUCT | A set of named fields. The field type can be different. | Struct('a',1,1,0) |
Chapter 2
Database Operations
- SHOW DATABASE:
show databases; CREATE DATABASE:
1
2
3
4
5
6
7
8
9Create [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT DELIMITED row_format]
[STORED AS file_format]
[LOCATION hdfs_path]USE DATABASE:
use database;- DELETE DATABASE:
DROP DATABASE [IF EXISTS] <database name>
Table Operations
CREATE TABLE :
Creates a table with the specified name.
If a table with the same name already exists, an exception is thrown;
The user can use the IF NOT EXIST option to ignore this exception.EXTERNAL :
External keyword allows users to create an external table, and specify a path to the actual data (LOCATION).
When you delete external table only deletes the metadata, not the data.ROW FORMAT DELIMITED] :
[ROW FORMAT DELIMITED]keyword is used to set the column separators supported by the created table when loading data.- [STORED AS file_format] :
specifies the file storage format. The default is TEXTFILE. If the file data is plain text, [STORED AS TEXTFILE] is used and then copied directly to HDFS from the local. - Partitioned tables can be created using the PARTITIONED BY statement. A table can have one or more partitions, and each partition exists in a separate directory.
- Both tables and partitions can perform a CLUSTERED BY operation on a certain column and put several columns into a bucket. You can also use SORT BY to sort the data. This can improve performance for specific applications.
File formats
TEXTFILE:
The TEXTFILE is default format. Data is not compressed. It has a large disk overhead and a large data parsing overhead.SEQUENCEFILE:
SEQUENCEFILE a binary file support provided by the Hadoop API, which is easy to use, splittable and compressible.RCFILE:
RCFILE is a combination of row and column storage.Custom format:
- When the user’s data file format cannot be recognized by the current Hive, you can customize the file format.
- Users can customize input and output formats by implementing inputformat and outputformat.
CREATE TABLE
- Create a normal table:
1
2create table Emp_table (id int,name string,no int)
row format delimited fields terminated by ',’ stored as textfile;
Note : A field separator is specified. HIVE only supports a single character separator. The default delimiter for hive is \ 001.
- Create a partitioned table
1
2create table Emp_partition (id int,name string,no int) partitioned by (dt string)
row format delimited fields terminated by ',’ stored as textfile ;
load data local inpath '/opt/niit/hive/test_hive.txt' overwrite into table test_partition partition (dt=’2015-06-15’);
Create a bucket table
1
2
3
4create table Emp_bucket (id int,name string,no int) partitioned by (dt string)
clustered by (id) sorted by(name) into 3 buckets
row format delimited fields terminated by ','
stored as textfile;Create an external table
1
2create external table Emp_external (id int,name string,no int)
row format delimited fields terminated by ',’ ;Copy table structure
1
create table Emp_like_table like Emp_bucket;
The above command copies table structure only, not content
Modify Table Operations
Increase partition
Syntax:ALTER TABLE table_name ADD partition_spec [ LOCATION 'location1'] partition_spec [ LOCATION 'location2' ]
Example:alter table Emp_partition add partition (dt='2015-06-15')Delete partition
Syntax:ALTER TABLE table_name DROP partition_spec
Example:alter table Emp_partition drop partition (dt='2015-06-15')
Description:After the partition is deleted, the metadata and data of the partition will be deleted together.
Table Operations
Table rename
Syntax:ALTER TABLE table_name RENAME TO new_table_name
Example:alter table Emp_partition rename to new_Emp_partition;
Description:The location of the data and the partition name do not change.Modify table column type
Syntax:ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
Example:alter table New_Emp_partition change name name1 String;Add column
Syntax:ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
Example:alter table New_Emp_partition add columns (age int);
Data loading
- Hive does not support insert operations using insert statements one by one. It also does not support update operations.
Hive不支持使用一个接一个的插入语句进行插入操作。它也不支持更新操作。 - The data is loaded into the established table in the manner of load.
数据以加载的方式加载到已建立的表中。 - Once the data is imported, it cannot be modified. We can either drop the entire table or create a new table and import the required data.
一旦数据被导入,它就不能被修改。 我们可以删除整个表,也可以创建一个新表并导入所需的数据。
Syntax:1
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
Ways to Import data in batches
- Load data and import to the specified table 加载数据并导入到指定的表
Import the local file system /home/data/aa.txt file into tab1,
syntax :1
load data local inpath '/home/data/aa.txt' into table tab1;
Import the file directly to the partition of the specified table. If the partition directory does not exist, hive will automatically create a partition directory, and then copy the data to the directory.
将文件直接导入指定表的分区。如果分区目录不存在,HIVE将自动创建一个分区目录,然后将数据复制到该目录。
- Load to the partition of the specified table 加载到指定表的分区
1
2LOAD DATA LOCAL INPATH '/home/admin/test/test.txt’
OVERWRITE INTO TABLE test_1 PARTITION(pt=’xxxx’)
The keyword [OVERWRITE] means to overwrite the data in the original table. If it is not written, it will not be overwritten.
关键字[OVERWRITE]表示覆盖原始表中的数据。如果不写,就不会被覆盖。
The keyword [LOCAL] means that the source of the file you are loading is a local file. If you do not write, the file is hdfs.
关键字[LOCAL]表示正在加载的文件的源是一个本地文件。如果不写,文件是HDFS。
- Import data using insert + select
By querying the table, the query results are imported into the specified table. 通过查询表,查询结果被导入到指定的表中。
Syntax :1
2INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement
INSERT into tab2 select * from tab1;
Import data using create+select
Create a new table and copy the data into this table.
创建一个新表并将数据复制到这个表中。
Syntax:1
2CREATE TABLE tablename1 AS select_statement1 FROM from_statement
CREATE table tab2 as select * from tab1;
Management tables
- The management table is also called an internal table.
管理表也称为内部表。 - Hive controls the life cycle of the table and the data in the table.
Hive控制表的生命周期和表中的数据。 - The data is stored in the directory set by the parameter hive.metastore.warehouse.dir in hive-site.xml.
数据存储在参数设置的目录中: - When Hive creates the internal tables, it moves the data to the path pointed to by the data warehouse.
当Hive创建内部表时,它将数据移动到数据仓库指向的路径。 - When a management table is deleted, the corresponding data in the table is also deleted at the same time.
删除管理表时,同时也删除表中相应的数据。 - We can create a management table by using the
create tablecommand.
我们可以使用create table命令来创建一个管理表。
External tables
- The data of the external table is not managed by hive, hive just establishes a reference.
外部表的数据不是由hive管理的,hive只是建立一个引用。 - When deleting an external table, only the metadata of the table is deleted, not the data.
删除外部表时,只删除表的元数据,而不删除数据。 - The external table is relatively more secure, and the data organization is more flexible, which facilitates the sharing of source data.
外部表相对更安全,数据组织也更灵活,这有助于共享源数据。 - Create table Use “create EXTERNAL table” to create external tables.
创建表使用创建外部表来创建外部表。
Partition Table
- Hive Select query scan the entire table which is time consuming.
在HIVE选择查询扫描整个表,这是耗时的。 - Sometimes only a part of the data in the table needs to be scanned, so the partition concept was introduced when the table was created.
有时只需要扫描表中的一部分数据,因此在创建表时引入了分区概念。 - A partitioned table refers to the partition space of the partition specified when the table was created.
分区表是指在创建表时指定的分区的分区空间。 - To create a partitioned table, you need to use the optional parameter partitioned by.
要创建分区表,需要使用可选的分区参数。 - A table can have one or more partitions, and each partition exists in the directory of the table folder in the form of a folder.
一个表可以有一个或多个分区,每个分区都以文件夹的形式存在于表文件夹的目录中。 - Table and column names are not case sensitive.
表名和列名不区分大小写。 - Partitions exist in the table structure in the form of fields.
分区以字段的形式存在于表结构中。 - You can see that the fields through the
describe tablecommand, but this field does not store the actual data , they are only the representation of the partition.
你可以通过describe table命令看到这些字段,但是这个字段并不存储实际的数据,它们只是分区的表示。
Types of partition table creation 分区表创建的类型
- Single partition: Which means that there is only one level folder directory under the table folder directory.
单分区: 这意味着在表文件夹目录下只有一个级别的文件夹目录。Statement: create table day_table (id int, content string) partitioned by (dt string); - Multi-partitioning: A multi-folder nesting mode appears under the table folder.
多分区: 在表文件夹下出现多文件夹嵌套模式。
Statement:create table day_hour_table (id int, content string) partitioned by (dt string, hour string); - Dual partition table, partitioned by day and hour, added dt and hour two columns in the table structure.
双分区表,按日和时进行分区,在表结构中增加了dt和时两列。 - Partition table contains Static partition and Dynamic partition
分区表包含静态分区和动态分区
Static Partition Table
- It is recommended to create a partitioned column before importing data.
建议在导入数据之前创建分区列。 - If you do not create the partition first, the partition is created automatically.
如果你没有首先创建分区,那么将会自动创建分区。
Dynamic Partition Table
- Dynamic partitioning can be automatically matched to the corresponding partition according to the data obtained by the query.
动态分区可以根据查询得到的数据自动匹配到相应的分区。
Example :1
2
3
4insert overwrite table logs_partition_ex
partition(stat_date='2001-01-02',province)
select member_id,name,province from logs_partition
where stat_date='2001-01-02’;
stat_date is called a static partition column, and province is called a dynamic partition column.
stat_date称为静态分区列,province称为动态分区列
In the select clause, dynamic partition columns need to be written in the order of partitioning, while static partition columns need not be written.
在select子句中,需要按分区顺序写入动态分区列,而不需要写入静态分区列。
In this way, all data with stat_date = '2001-01-02' will be inserted into /user/hive/warehouse/logs_partition/stat_date=2001-01-02/ under different subfolders according to the difference of the source.
这样,根据来源的不同,所有stat_date = '2001-01-02'的数据将被插入到/user/hive/warehouse/logs_partition/stat_date=2001-01-02/的不同子文件夹中。
The province sub-partition corresponding to the data does not exist, it will be automatically created
对应的province子分区数据不存在,将会自动创建
Related parameters about dynamic partitioning: 动态分区相关参数:hive.exec.dynamic.partition.mode. This value defaults to strict, which means that all columns are not allowed to be dynamic. Set hive.exec .dynamic.partition.mode = nonstrict
动态分区允许所有分区的列都是动态分区的列,但是你首先必须设置一个参数hive.exec.dynamic.partition.mode。该值默认为strict,这意味着不允许所有列都是动态的。 hive.exec .dynamic.partition.mode = nonstricthive.exec.max.dynamic.partitions.pernode (default value:100):The maximum number of partitions that each mapreduce job can create. If this number is exceeded, an error will be reported.hive.exec.max.dynamic.partitions.pernode:每个mapreduce作业可以创建的最大的分区数。如果超过这个数字,将会报告一个错误。hive.exec.max.dynamic.partitions (Default value is 1000): The maximum number of all partitions allowed in a dml statement.hive.exec.max.dynamic.partitions (Default value is 1000): dml语句中允许的所有分区的最大数。hive.exec.max.created.files (The default value is 100,000): The maximum number of files allowed for all mapreduce jobs.hive.exec.max.created.files (The default value is 100,000):所有mapreduce作业允许的最大文件数。
Bucket table
- Hive can be further organized into buckets for each table (table or partition).
Hive可以进一步的组织到每个表(表或分区)的桶中。 - Buckets are more fine-grained data range divisions.
桶(Buckets)是更细粒度的数据范围划分。 - Hive is also an organization that buckets a certain column.
Hive也是一个存储特定列的组织。 - Hive determines the bucket in which the record is stored by hashing column values and dividing by the number of buckets.
Hive通过散列列值并除以桶(Bucket)的数量来确定存储记录的桶(Buckets) 。 - There are two reasons to organize tables (or partitions) into buckets:
将表(或分区)组织到桶(Buckets)中有两个原因:- Get higher query processing efficiency. 获得更高的查询处理效率。
- Buckets add extra structure to the table, which Hive can take advantage of when processing some queries. Specifically, joining two tables that have buckets divided on the same columns (including the joining columns) . 桶(Buckets)为表添加了额外的结构,Hive在处理某些查询时可以利用它。具体来说,连接两个具有相同列上分隔桶(Buckets)的表(包括连接列)。
- Make sampling more efficient. 提高采样效率。
When dealing with large-scale data sets, if you can test run a small amount of data in the data set during the development and modification of the query, it will bring a lot of convenience.
在处理大型数据集时,如果在查询的开发和修改过程中,能够在数据集中测试运行少量的数据,将会带来很大的方便。
Bucketing syntax: Bucketing语法:1
2CREATE TABLE bucketed_user (id INT, name STRING)
CLUSTERED BY (id) SORTED BY(id) INTO 4 BUCKETS;
- The CLUSTERED BY clause specifies the columns used to divide the bucket and the number of buckets to be divided.
CLUSTERED BY子句指定用于划分桶(Bucket)的列和要划分的桶(Buckets)的数量。 - Optional Sorted by clause can be used to sort data inside bucket based on column specified.
- Hive uses a hash of the value and divides the result by the number of buckets to get the remainder, which is id.hash ()% 4. The data is put into the bucket based on this result.
Hive使用hash值,并将结果除以桶(Buckets )的数量来得到剩余部分,即id.hash()% 4。根据这个结果将数据放入桶(Bucket )中。 - To populate the bucket table with data, you need to set the hive.enforce.bucketing property to true. 要用数据填充桶表,你需要设置hive.enforce.bucketing属性设为真。
Remember buckets are created in power of 2
桶的数量要是2的次方
1 bucket = 1 file = 1 reducermapred.reduce.tasks=64
Bucket table store data
- Sometimes partitioning is not suitable in that case create bucket.
- Disadvantage of partition
- Partitions can increase as new values are inserted in column.
- Partition with small size can degrade the performance.
- Advantage of bucket
- The number of buckets is fixed and there is no data fluctuation
- The number of Reduces written to the bucket is fixed
HQL
SELECT Command
Syntax1
2
3
4
5SELECT [ALL | DISTINCT] select_expr, select_expr, ...FROM table_reference
[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY | ORDER BY col_list]
] [LIMIT number]
- We can use
ALLoption to retrieve all records andDISTINCToptions to retrieve all records except duplicate one.
我们可以使用ALL选项来检索所有记录,使用DISTINCT选项来检 索除重复记录之外的所有记录。 - The default is
ALL默认值是ALL - Where condition is same as SQL and support
ORandANDcondition
Where 条件与SQL相同,支持 OR 和 AND 条件 - 0.9 version supports
BETWEEN,IN,NOTIN but does not supportEXISTandNOT EXIST
0.9版本支持BETWEEN, IN, NOT IN,但不支持 EXIST 和 NOT EXIST ORDER BYclause sort the data globally and there is only one Reduce task
ORDER BY子句对数据进行全局排序,并且只有一个Reduce任务SORT BYsorts the data locally
SORT BY按本地数据排序- Limit can limit the number of records queried.
Limit可以限制查询记录的数量。 - We can print the column name By 我们可以用以下打印列名
set hive.cli.print.header = true; - Queries that specify columns using regular expressions
使用正则表达式对指定列的查询Select id,name,'pv.*' from log WHEREclause : The where condition is a Boolean expression.
where条件是一个Boolean表达式
Partition-based query 基于分区的查询
- Normally, a SELECT query scans all tables (except sampling).
通常来说,SELECT查询扫描所有表(抽样除外)。 - If the table is created with the
PARTITIONED BYclause, the query can be partitioned and pruned, and a part of the table is scanned according to the partition range specified by the query.
如果使用PARTITIONED BY子句创建表,则可以对查询进行分区和 修剪,并根据查询指定的分区范围扫描表的一部分。 - Currently, Hive specifies partitions in the where clause or the ON clause of JOIN and will perform partition trimming.
目前,Hive在JOIN的where子句或ON子句中指定分区,并将执行 分区修剪。
Limit statement
- The Limit statement limits the number of rows returned.
Limit语句限制返回的行数 - Example :
select * from pv limit 3;
Column alias (列别名)
- Example : select userid as uid from pv;
Nested select (嵌套的选择)
- Hive statements support nested select statements.
Hive语句支持nested select语句
Like and RLike
- Like is a standard SQL statement, and RLike is an extension of Hive. You can specify matching conditions through java regular expressions.
Like是一个标准的SQL语句,而RLike是Hive的扩展。可以通过java 正则表达式for指定匹配条件
Example:Select name,address.street from employees where address.street RLIKE '.*(A|B).*'Select name,address.street from employees where address.street LIKE 'R%'
Group by
- Group by is used with aggregate functions (avg, sum, min, max, count) to group results by one or more columns:
Group by与聚集函数一起使用,将结果按一个或多个列分组:
Example :Select count(id) from t_pv group by id;
HAVING clauseSELECT col1 FROM t1 GROUP BY col1 HAVING SUM(col2) > 10SELECT col1 FROM (SELECT col1, SUM(col2) AS col2sum FROM t1 GROUP BY col1) t2 WHERE t2.col2sum > 1
(Both queries will give same output) (两个查询将给出相同的输出)
Join statement
支持 INNER JOIN, FULL JOIN, LEFT JOIN, RIGHT JOIN
Syntax
join_table:1
2
3table_reference JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition
| table_reference LEFT SEMI JOIN table_reference join_condition
table_reference:
table_factor | join_table
table_factor:
tbl_name [alias] | table_subquery alias | ( table_references )
join_condition:
ON equality_expression_r( AND equality_expression )* equality_expression:
expression = expression
Reference
- NIIT

